Segregated fits.
This variant [of
Segregated free lists] uses an
array of free lists,
with each array holding free blocks within a size class.
When servicing a request for a particular size, the free
list for the corresponding size class is searched for a
block at least large enough to hold it. The search is
typically a sequential fits search, and many significant
variations are possible.
Typically first fit
or next fit is used. It is often pointed out that the use
of multiple free lists makes the implementation faster
than searching a single free list. What is sometimes
not appreciated is that this also affects the placement
in a very important way - the use of segregated lists
excludes blocks of very different sizes, meaning good
fits are usually found - the policy therefore embodies
a good fit or even best fit strategy, despite the fact that
it's often described as a variation on first fit.
If there is not a free block in the appropriate free
list, segregated fits algorithms try to find a larger
block and split it to satisfy the request. This usually
proceeds by looking in the list for the next larger size
class if it is empty, the lists for larger and larger sizes
are searched until a fit is found. If this search fails,
more memory is obtained from the operating system
to satisfy the request. For most systems using size
classes, this is a logarithmic-time search in the worst
case. (For example for powers-of-two size classes, the
total number of lists is equal to the logarithm of the
maximum block size. For a somewhat more refined series,
it is still generally logarithmic, but with a larger
constant factor.)
In terms of policy, this search order means that
smaller blocks are used in preference to larger ones,
as with best fit. In some cases, however, the details
of the size class system and the searching of size-class
lists may cause deviations from the best fit policy.
Note that in a segregated fits scheme, coalescing
may increase search times. When blocks of a given
size are freed, they may be coalesced and put on dif-
ferent free lists (for the resulting larger sizes) when
the program requests more objects of that size, it may
have to find the larger block and split it, rather than
still having the same small blocks on the appropriate
free list. (Deferred coalescing can reduce the extent of
this problem, and the use of multiple free lists makes
segregated fits a particularly natural context for deferred
coalescing.)
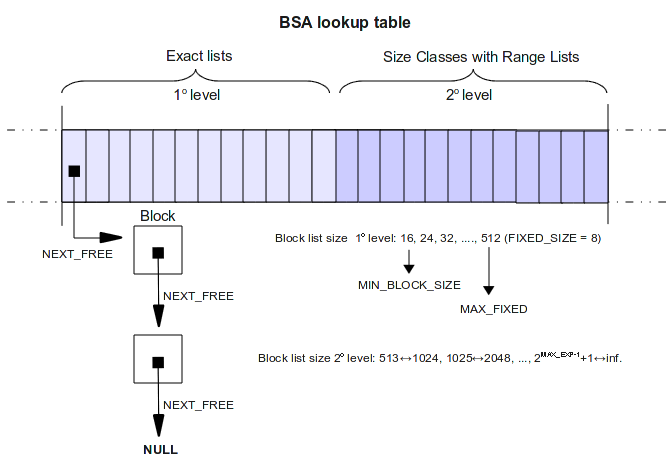
Segregated fits schemes fall into three general categories:
-
Exact Lists. In exact lists systems, where there is
(conceptually) a separate free list for each possible
block size. This can result in a very
large number of free lists, but the "array" of free
lists can be represented sparsely. Standish and
Tadman's "Fast Fits" scheme uses an array of
free lists for small size classes, plus a binary tree
of free lists for larger sizes (but only the ones that
actually occur).
-
Strict Size Classes with Rounding. When sizes are
grouped into size classes (e.g., powers of two),
one approach is to maintain an invariant that all
blocks on a size list are exactly of the same size.
This can be done by rounding up requested sizes
to one of the sizes in the size class series, at some
cost in internal fragmentation. In this case, it is
also necessary to ensure that the size class series
is carefully designed so that split blocks always
result in a size that is also in the series otherwise
blocks will result that aren't the right size for any
free list.
-
Size Classes with Range Lists. The most common
way of dealing with the ranges of sizes that
fall into size classes is to allow the lists to conain
blocks of slightly different sizes, and search
the size lists sequentially, using the classic best
fit, first fit, or next fit technique (The
choice affects the policy implemented, of course,
though probably much less than in the case of
a single free list.) This could introduce a linear
component to search times, though this does not
seem likely to be a common problem in practice,
at least if size classes are closely spaced. If it
is, then exact list schemes are preferable.
An effcient segregated fits scheme with general
coalescing (using boundary tags) was described and
shown to perform well in 1971 PSC71, but it did
not become well-known Standish and Tadman's ap-
parently better scheme was published (but only in a
textbook) in 1980, and similarly did not become par-
ticularly well known, even to the present. Our impres-
sion is that these techniques have received too little
attention, while considerably more attention has been
given to techniques that are inferior in terms of scala-
bility (sequential fits) or generality (buddy systems).
Apparently, too few researchers realized the full
significance of Knuth's invention of boundary tags
for a wide variety of allocation schemes - boundary
tags can support fast and general splitting and coa-
lescing, independently of the basic indexing scheme
used by the allocator. This frees the designer to use
more sophisticated higher-level mechanisms and policies
to implement almost any desired strategy. (It
seems likely that the original version of boundary tags
was initially viewed as too costly in space, in a time
when memory was a very scarce resource, and the
footer optimization simply never became well-
known.).