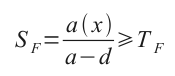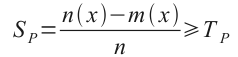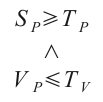BSA++
Motivations behind BSA++
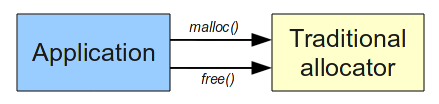
Traditional allocators usually are designed in order to work
with every type of application. They are not optimazed for a
specific pattern of allocation. We can think an interaction
between an application and an allocator in this way:
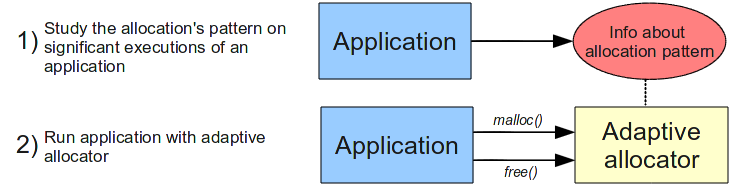
Instead with BSA++, we add a preliminary phase, when a tool
studies the pattern of allocation for an application and
elaborates a configuration file for BSA++. Then, we can run
our application with BSA++. So basically, the interaction
becames:
Methodology: privileged block sizes
An application during its execution can allocate different
sizes of block but often it uses more frequently
one (or some) block size than others. At same time, the allocator
(such as BSA) can spent very much time in order to coalesce and
split these blocks despite it was not useful for that
application.
On this observation, we decide to develop an improved version
of BSA, called BSA++, that does not coalesce or split blocks if
they have some particular sizes. These sizes are decided, before
the allocator starts, during the analysis of application's
allocation trace (see
MallocLabTools for more information about the tools used).
Furthermore BSA++, in order to speedup its job, uses exact lists
for the frequent blocks.
Block size frequency: frequency score
At the beginning in order to judge when a block size has to be
considered as frequent, we simply count how much times
a block size was requested; if it exceeds a threshold (
ALLOC_OPS_THRESHOLD), the size is considered frequent
and BSA++ is optimized for it.
So this is the frequency score:
where:
- a(x): number of re/allocations for block size of x bytes
- a: number of all operations
- d: number of all deallocations
This approach is not very good because it not study how
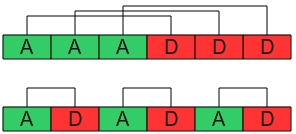
the blocks are allocated or deallocated. For example
it not distinguishes these two different situations (blocks
have all the same size):
In the first scenario, it isn't useful disable split and
coalesce of the blocks (suppose that we have other requests
after those in the image). Instead, in the second case, can be
convienient to disable split and coalesce.
Block size frequency: popularity score
We define popularity score as:
where:
- n(x): number of allocations for block size of x bytes
- m(x): max simultaneous allocations for block size of x bytes
- n: number of all allocations
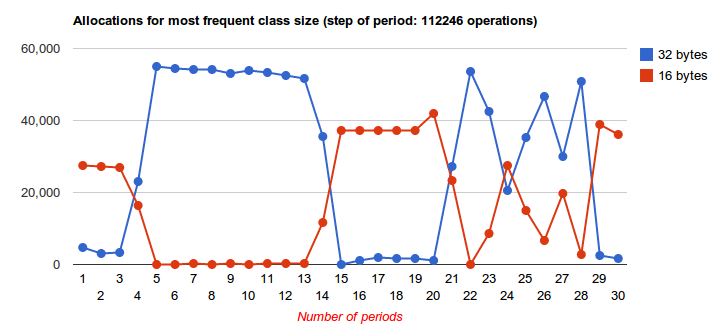
Espresso shows us that only with (too) high threshold we
can protect against worst-case space scenarios. But with high
threshold we lose all benefits of BSA++. This is a
graph of how espresso allocates the two most frequent
block size:
Block size frequency: average popular score (AVG)
We try to identify when an application (like Espresso) allocates
frequently a block size but with not a costant pattern (for
example it alternates requests for two different block sizes).
So, we compute the popularity score every (N / 30) operations
(where N is the number of all operations) and then calculate
the average value. Also with average popular score we need
an high threshold in order to protect against worst-case space
scenarios.
Block size frequency: variance popular score (VAR)
Finally we found a better method to judge the behaviour of an
application. We compute the popularity score every (N / 30)
operations (where N is the number of all operations) and then
calculate the
variance. We optimize BSA++ for a block size only if it
has a sufficient popularity score (not too high threshold)
and limited variance popularity score.
Source code
Get BSA/BSA++ here.